Dit d'una altre forma: Groovy permet simplificar el codi de les aplicacions de bases de dades. Res millor que un exemple.
En l'exercici que es proposa faré us de la base de dades HSQLDB, que és el motor de base de dades que es fa servir, per exemple, a les suites ofimàtiques OpenOffice.org i LibreOffice.
Per a poder utilitzar HSQLDB des de Groovy cal afegir el hsqldb.jar a les llibreries que es carreguen a l'inici. En el cas que m'ocupa, un Groovy sobre Linux Ubuntu, cal revisar el fitxer $GROOVY_HOME/conf/groovy-starter.conf en el que es pot trobar el següent:
# load user specific libraries
load !{user.home}/.groovy/lib/*.jar
Tinc l'HSQLDB instal·lat a una carpeta apart. Per tant, per evitar duplicitats, en comptes de posar l'hsqldb.jar a $HOME/.groovy/lib, el que faig és posar en aquesta carpeta un enllaç simbòlic al jar que hi ha a la carpeta on està desplegat el motor de la base de dades.
A continuació, creo una base de dades del tipus fitxer i standalone. Cal dir que HSQLDB pot funcionar en "mode servidor" o bé en "mode standalone". A més, també pot funcionar o bé mantenint les dades en un fitxer, o bé "mantenint" les dades en memòria (evidentment, només es "mantenen" mentre el procés és viu).
Per a crear la taula es pot fer servir, per exemple, l'OpenOffice.org/LibreOffice Base. En aquest cas caldria afegir hsqldb.jar al classpath de l'OOo/LO (eines - opcions - java)

i camí a les classes:

i, a continuació, crearia una base de dades del tipus Jdbc.

En el meu cas, la base de dades la fico a Documentes/databases/hsqldb/prova.db, per tant la URL JDBC que he de fer servir és:
jdbc:hsqldb:/home/albert/Documents/databases/hsqldb/prova.db
i el driver:
org.hsqldb.jdbc.JDBCDriver
(canviar aquesta imatge)

Això em permetrà fer servir l'assistent de l'OOo/LO per a definir la taula i els tipus de dades. Creo una taula diccionari amb tres columnes: id (enter), nom (varchar de 100) i valor (varchar de 100).

I un cop creada la taula, la informo amb algunes dades de prova:

Probablement la classe més útil de Groovy per al treball amb bases de dades sigui groovy.sql.Sql. Aquesta classe és una mena de navalla suïssa que proporciona una varietat de mètodes per a fer gairebé totes les tasques comuns amb taules.
La pàgina de la documentació de groovy.sql.Sql ens explica les possibilitats d'aquesta navalla suïssa.
Per a utilitzar-la cal importar-la
import groovy.sql.Sql
A continuació puc configurar la connexió a la base de dades que he creat fa un moment:
def ds = [url:'jdbc:hsqldb:/home/albert/Documents/databases/hsqldb/prova.db',
user:'sa',
password:'',
driver:'org.hsqldb.jdbc.JDBCDriver']
def sql = Sql.newInstance(ds.url, ds.user, ds.password, ds.driver)
Consulto la taula que he creat amb el OOo/LO amb el potent mètode eachRow, adonem-nos com la fila en curs és accessible amb 'it':
sql.eachRow("select * from public.\"diccionari\" where \"id\" >= 3") {
println "id = ${it.id}; nom = ${it.nom}; valor = ${it.valor}"
}
i el resultat és
albert@athena:~/Workspace/wk-groovy/prova-jdbc$ groovy provabd.groovy
id = 3; nom = nom3; valor = valor3
id = 4; nom = nom4; valor = valor3
id = 5; nom = nom5; valor = valor5
Creo una nova taula i la informo amb dades. Cal tenir en compte algunes particularitats de l'SQL de l'HSQLDB: els noms de les taules han d'anar precedides de l'esquema; els noms de taules, columnes i d'altres objectes van entre cometes dobles; els literals van entre comentes simples.
sql.execute '''
create table public.\"traductor\" (
\"id\" integer not null,
\"catala\" varchar(100),
\"castella\" varchar(100),
)
'''
Faig insert de dades amb diferents mètodes:
- fent servir la sintaxi amb '''
sql.execute '''
insert into public.\"traductor\"(\"id\",\"catala\",\"castella\") values (1, 'catala 1','castella 1')
'''
println "inserta fila 1"
- fent servir la sintaxi de preparedStatement de JDBC
def params = [2, 'catala 2', 'castella 2']
sql.execute("insert into public.\"traductor\" (\"id\", \"catala\", \"castella\") values (?, ?, ?)", params)
println "inserta fila 2"
params = [3, 'catala 3', 'castella 3']
sql.execute("insert into public.\"traductor\" (\"id\", \"catala\", \"castella\") values (?, ?, ?)", params)
println "inserta fila 3"
- fent servir la sintaxi GString
def map = [id:4, catala:'català 4', castella:'castellà 4']
sql.execute("insert into public.\"traductor\" (\"id\", \"catala\", \"castella\") values ($map.id, $map.catala, $map.castella)")
println "inserta fila 4"
Visualitzo els resultats amb eachRow, ara fent servir el paràmetre fila a la closure, en comptes d'it.
sql.eachRow("select * from public.\"traductor\"") {fila ->
println "id = $fila.id; català = $fila.catala; castellà = $fila.castella"
}
Després d'aquestes accions, tinc les dues taules amb dades, com puc veure amb l'OOo/LO

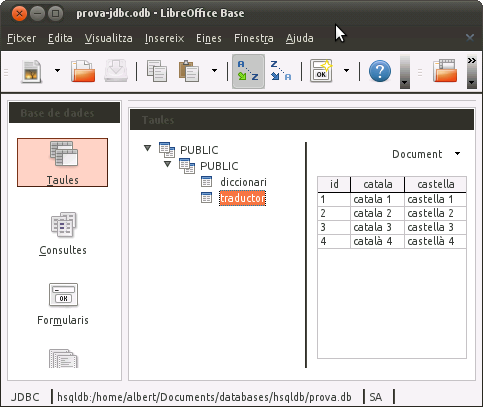
He fet inserts, evidentment també es poden fer update, delete... fent servir execute, o millor executeUpdate, que em retorna una llista de les files afectades.
eachRow admet paginació. He afegit algunes dades més a la taula traductor i la visualitzo, primer tota i després mostrant només quatre files a partir de la fila tres:
println "mostra la taula \"traductor\""
sql.eachRow("select * from public.\"traductor\"") {fila ->
println "id = $fila.id; català = $fila.catala; castellà = $fila.castella"
}
println "mostra 4 files de la taula \"traductor\" a partir de la fila 3"
sql.eachRow("select * from public.\"traductor\"", 3, 4 ) {fila ->
println "id = $fila.id; català = $fila.catala; castellà = $fila.castella"
}
El resultat és:
mostra la taula "traductor"
id = 1; català = catala 1; castellà = castella 1
id = 2; català = catala 2; castellà = castella 2
id = 3; català = catala 3; castellà = castella 3
id = 4; català = català 4; castellà = castellà 4
id = 5; català = catala 5; castellà = castella 5
id = 6; català = catala 6; castellà = castella 6
id = 7; català = catala 7; castellà = castella 7
id = 8; català = català 8; castellà = castellà 8
mostra 4 files de la taula "traductor" a partir de la fila 3
id = 3; català = catala 3; castellà = castella 3
id = 4; català = català 4; castellà = castellà 4
id = 5; català = catala 5; castellà = castella 5
id = 6; català = catala 6; castellà = castella 6
La classe groovy.sql.Sql té altres mètodes que també permeten augmentar la productivitat del desenvolupament, que s'afegeixen al fet que els scripts en Groovy no requereixen compilació.
groovy.sql.Sql també té mètodes que retornen ResultSet de jdbc, permetent el tractament típic de Java.
El package groovy.sql també inclou la classe DataSet que deriva de groovy.sql.Sql i que permet fer queries a la base de dades fent servir operadors i noms de camps de Groovy en comptes de crides a API JDBC i noms de taules i columnes. Un petit exemple:
Primer de tot, cal importar DataSet
import groovy.sql.DataSet
i ja el puc fer servir:
primer mostro el contingut de la taula amb eachRow d'Sql i després fa la query amb DataSet
println "mostra la taula \"traductor\""
sql.eachRow("select * from public.\"traductor\"") {fila ->
println "id = $fila.id; català = $fila.catala; castellà = $fila.castella"
}
println "mostra valors amb id entre 3 i 7 fent servir la classe DataSet"
def traduccions = sql.dataSet("public.\"traductor\"")
def filtrat = traduccions.findAll {it."\"id\"" >= 3 && it."\"id\"" <= 7 }
filtrat.each { fila ->
println "id = $fila.id; català = $fila.catala; castellà = $fila.castella"
}
El resultat és el següent
mostra la taula "traductor"
id = 1; català = catala 1; castellà = castella 1
id = 2; català = catala 2; castellà = castella 2
id = 3; català = catala 3; castellà = castella 3
id = 4; català = català 4; castellà = castellà 4
id = 5; català = catala 5; castellà = castella 5
id = 6; català = catala 6; castellà = castella 6
id = 7; català = catala 7; castellà = castella 7
id = 8; català = català 8; castellà = castellà 8
mostra valors amb id entre 3 i 7 fent servir la classe DataSet
id = 3; català = catala 3; castellà = castella 3
id = 4; català = català 4; castellà = castellà 4
id = 5; català = catala 5; castellà = castella 5
id = 6; català = catala 6; castellà = castella 6
id = 7; català = catala 7; castellà = castella 7
En aquest exemple les particularitats de HSQLDB pel que fa als noms de taules i columnes entre cometes no permeten aprofitar la simplificació de fer servir els noms de les columnes com si fossin noms de camps Groovy de l'objecte it. Però, si més no, es permet veure l'ús de l'operador && per a construir el "where" del Dataset
I finalment, per acabar...
// tanca la connexió
sql.close()
Cap comentari:
Publica un comentari a l'entrada